こんにちは 株式会社フィードフォース2020年入社の機械学習エンジニア 八百 俊哉と申します。
今回は、solafuneで開催された「夜間光データから土地価格を予測」という機械学習コンペに参加したので工夫した点や反省点などを紹介します。
コンペ参加の目標設定としては、「賞金獲得!!(4位以内)」を設定していましたが、36位/201人中と目標達成できませんでした。残念な結果に終わってしまいましたが、多くのことを学ぶことができました。
参加経緯
私は、2020年10月から2021年2月ごろまで顧客の課題解決のために機械学習を応用する方法を学ぶためにAI Questというイベントに参加していました。そのイベントをきっかけに私は精度の高いモデルや良い特徴量を作成することに興味を持ちました。
そこでより多くのコンペに参加することで精度を上げるためのノウハウを身に付けたいと思ったことが今回のコンペに参加したきっかけです。
また、今回参加したコンペは与えられている特徴量が4つしかないので、初心者が参加しやすいコンペだったということも魅力的なポイントでした。
課題と与えられているデータ
課題としては、「夜間光データを元に土地価格を予測するアルゴリズムを開発する」というものです。 使用可能なデータとしては、以下のものが与えられました。
- 地域ごとのデータ・・・地域固有のID
- 年代・・・1992~2013年まで
- 土地の平均価格(目的変数)・・・1992~2013年まで
- 夜間光量の平均値・・・0~63までのレンジでその地域の平均光量
- 夜間光量の合計値・・・その地域の合計光量
全体構成
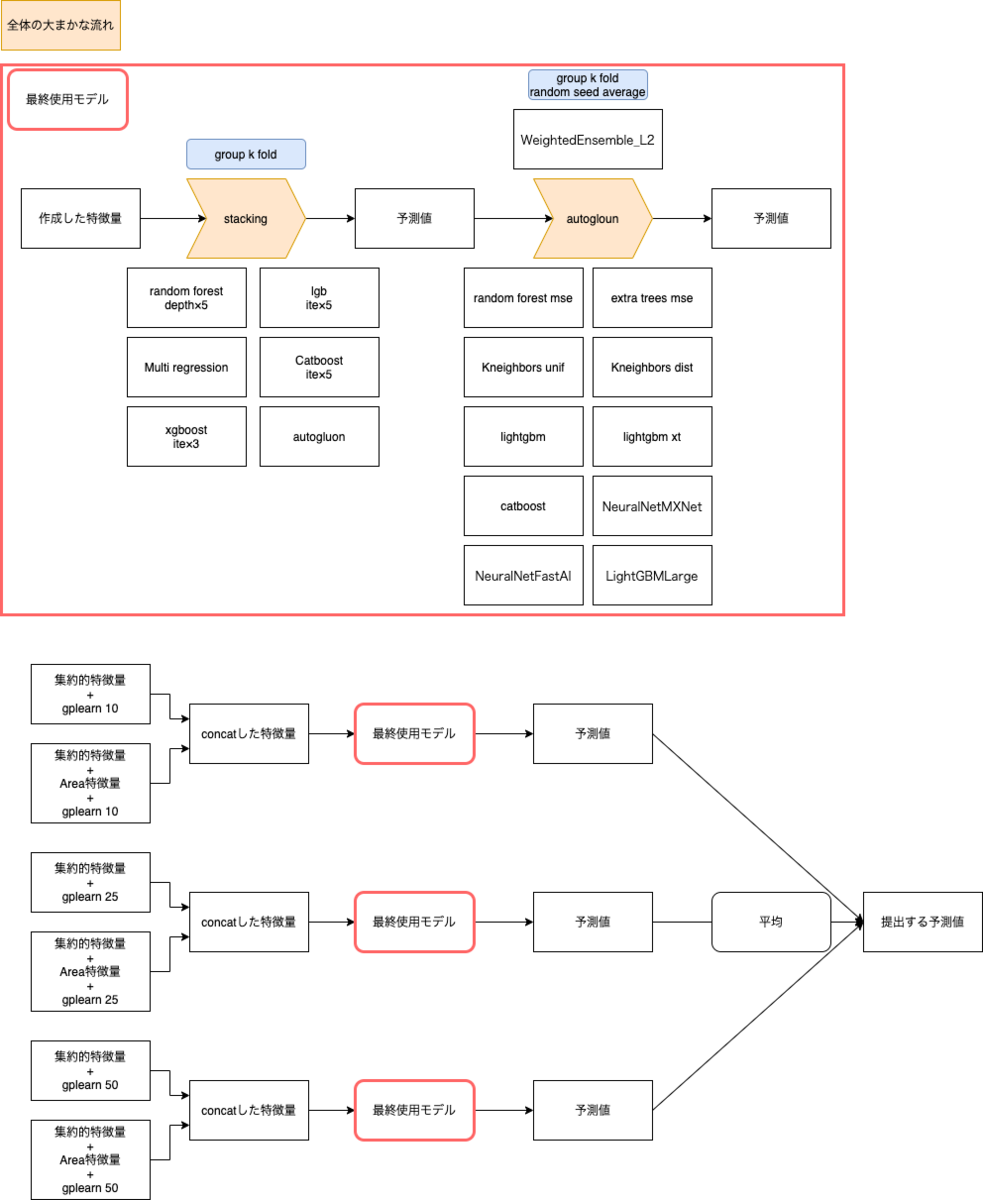
今回最終submitとして選択したモデルの全体構成は以下です。
前処理に関して
集約的特徴量について
集約的特徴量の作成にあたってはmasato8823 (@mst_8823) | TwitterさんがBaseLineとして公開されていた以下のものを使用しました。
作成した特徴量としては以下です。
| 面積 | 夜間光量の合計値/夜間光量の平均値を行い面積を算出した |
| PlaceID,Yearごとの統計情報 | PlaceID,Yearをキーとして平均光量、合計光量、面積のmin,max,median,mean,std,max-min,q75-q25を算出した |
| PlaceID をキーにしたグループ内差分 | 平均光量、合計光量の年ごとの差分を算出した |
| PlaceID をキーにしたグループ内シフト | 平均光量、合計光量の年ごとの値をシフトした |
| ピボットテーブルを用いた特徴量 | index=PlaceID,columns=Yearとして平均光量、合計光量、面積のピボットテーブルを作成し、PCAで次元削減したものを算出した |
| PlaceIDをキーにしたグループ内相関係数 | PlaceIDごとにデータを集約しYearと平均光量、合計光量、面積との相関係数を算出した |
| 平均光量が63であった回数 | 平均光量の最大値が63であることから平均光量が63である数を追加した |
Area特徴量について
先ほど集約的特徴量についてで面積の求め方について書きました。面積=合計光量/平均光量で算出しています。ここで求められる土地の面積は、年が変化しようと変化しないと思われますが、実際のデータを確認すると年が変化すると面積も変化していました。
そこで合計光量/平均光量より算出された面積をPlaceIDをキーとして平均を取ったものを新たな面積としました。 新たな面積が求まると 新たな合計光量 = 平均光量×新たな面積,新たな平均面積 = 合計光量/新たな面積 が求まります。
これらより求まる新たな合計光量、新たな平均光量、新たな面積を元々の合計光量、平均光量、面積と置き換えて集約的特徴量の作成を行いました。
gplearnについて
上で紹介した集約的特徴量とArea特徴量のそれぞれに対してgplearnというライブラリを用いて新たな特徴量を作成しました。このライブラリは遺伝的アルゴリズムにより目的変数をよく表している変数を作成してくれるものです。
このライブラリを用いて新しい特徴量を10個,25個,50個作成し、元々の集約的特徴量、Area特徴量と組み合わせてそれぞれに対して予測を行いました。
gplearnでの特徴量作成については以下のサイトが参考になります。
モデル構築に関して
モデルの構築としてはgroup k fold(fold=5)でStackingのモデルを採用しました。
1層目はrandom forest,lgb,multi regression,catboost,xgboostに加えてAutoMLのAutogluonを採用しました。
Autogluonは以下のようにデータを渡すだけで、11個のモデルを検証し最後に出力結果を重量平均で作成してくれます。
predictor = TabularPredictor(
label='label',
problem_type='regression',
eval_metric='root_mean_squared_error', # 評価指標
)
X_train['label'] = y_train
X_test['label'] = y_test
predictor.fit(
train_data=X_train,
tuning_data=X_test, # これを渡さない場合はランダムスプリット
time_limit=None, # おおよその時間制限を設けられる
)
そして2層目は1層目でも採用しているAutogluonで出力を作成しました。
感想・反省点
Public Scoreの時点では6位と賞金獲得の可能性が十分にありましたが、Private Scoreでは36位と大幅にshake downしてしまいました。今回目標達成できなかった理由としては以下の2つが考えられます。
1 CVの値とPublic ScoreからPrivate Scoreについて考えられなかった
1つ目の要因としては、Public Scoreが下がることのみを考えてモデルの改善・特徴量の作成を行っていたということです。その時CVの値とPublic Scoreをどこかに記録しておけばよかったのですが、どこにも保存せずPublic Scoreが下がることが最も良いことであると捉えていました。実際は、CVが下がったモデル・特徴量においてPublic Scoreも同じように下がることが望ましく、その記録を取っておくべきでした。
実際これまで提出していたファイルの中にPrivate Scoreが0.48774というものがあり、このファイルを最終提出としておけば3位に入ることができていました。しっかりとPrivate Scoreに効いているであろう提出ファイルが選べるようにCVとPublic Scoreに着目できるようにならないといけないと感じました。
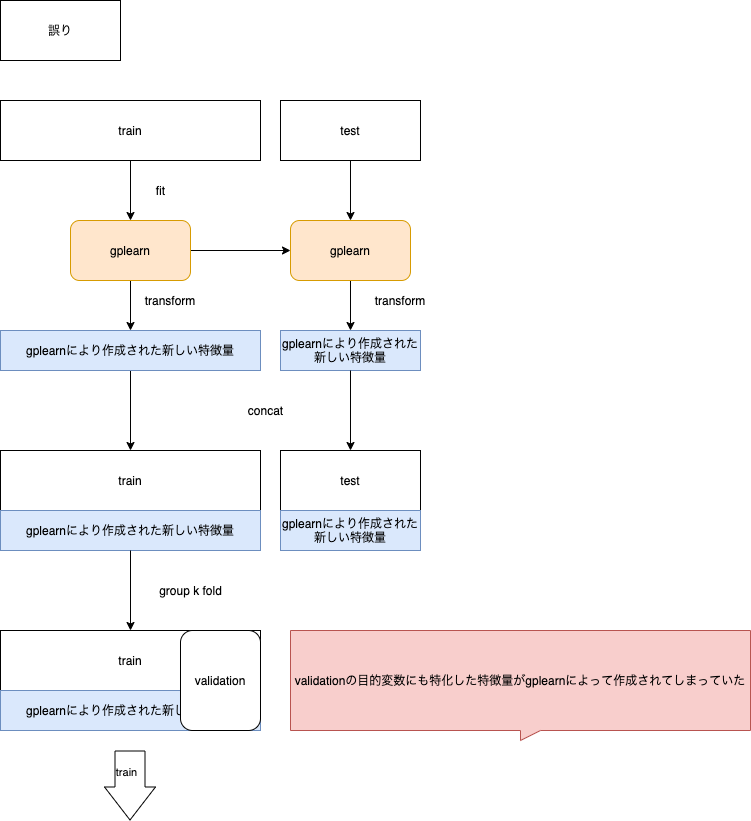
2 gplearnを行う位置が悪かった
2つめは、group k foldを行う前にgplearnを行ったことによって、validationの目的変数が確認できる状態でgplearnが特徴量作成を行ってたことです。これは本来見ることができないデータを確認しながらデータ生成を行っていることになるので過学習を引き起こす可能性がありました。
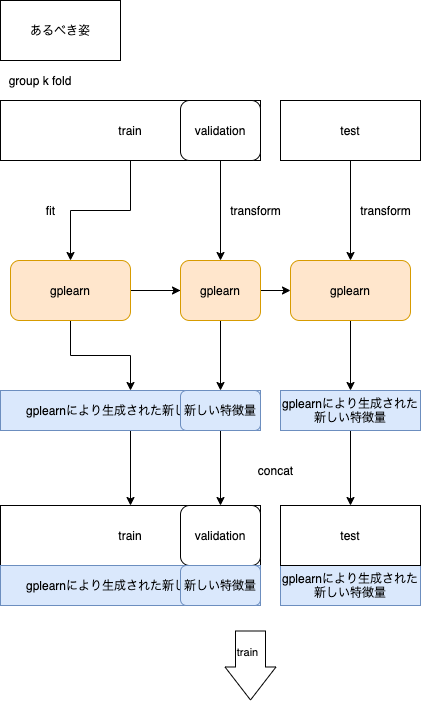
あるべき姿としては、group k foldでtrainをtrain,validationに分割した後にtrainのみのデータを用いてgplearnをfitさせるべきだったと思います。
次回コンペでは
今回のコンペを通じて集約的特徴量の作成方法、Stackingの実装方法、gplearnの実行位置、CVとPublic Scoreの関係性の重要度について学ぶことができました。 テーブルコンペ において有効な手法を多く学ぶことができたので、次回参加するコンペでは賞金獲得を目標に頑張ります!!