こんにちは データサイエンティストの八百俊哉です。最近は家でカクテルを作ることにはまっています。
今回はEC BoosterのクライントのECサイトのタイトルと説明文を用いることで、どのカテゴリの商品を扱っているのか予測する仕組みを作成しましたので、その方法を紹介します。
弊社のサービスEC Boosterは、Google ショッピング広告の自動運用による自社EC自動集客サービスです。主要ECシステムと連携することで、Google の検索結果画面に画像付きで自社商品を訴求することが可能となります。
分析背景
EC Boosterを利用いただくことで、Google ショッピング広告を自動運用することができます。 Googleショッピング広告では広告出稿する際に、Googleが自動的にそれぞれの商品にgoogle product categoryというカテゴリ情報を割り当てます。
しかしながら、Googleが自動的に割り振った商品ごとのカテゴリ情報はEC Booster側からは確認することができません。
Google's category of the item (see Google product taxonomy). When querying products, this field will contain the user provided value. There is currently no way to get back the auto assigned google product categories through the API. https://developers.google.com/shopping-content/reference/rest/v2.1/products?hl=en#Product.FIELDS.google_product_category
商品ごとに割り振られたカテゴリがわからないと、それぞれのクライントがどのような商品を扱っているのかわからなくなります。
その結果、クライアントの実績を取扱商品カテゴリごとに集計したり、扱っているカテゴリごとのサポートを行ったりすることができなくなってしまいます。
そこで今回はクライントごとに取扱商品カテゴリをEC Booster側で予測することで、上に挙げたような課題を解決するような仕組みを作成しました。
学習・予測に必要なデータの収集
EC Boosterは現在有料プラン約300のクライントとフリープラン約2000のクライントにご利用いただいております。(2022年5月第2四半期 決算説明資料より)
学習データ生成のために、有料プランユーザーを中心に約470のクライントに対して手動でカテゴリを割り振るという作業を実施しました。また、このデータの作成はそれぞれのクライントのホームページを目視で確認し、適切なカテゴリを割り振りました。
次に学習・予測に必要な入力データの収集を行いました。今回はそれぞれのクライントのタイトルと説明文を用いて学習をします。
そのため以下に示すようにそれぞれのホームページからtitleとdescriptionのスクレイピングを行いました。

それぞれのtitleとdescriptionが収集できると以下のようなデータになります。
| shop_id | 手入力カテゴリ | title | description |
|---|---|---|---|
| A | カテゴリA | レトロな服を買うならA | レトロな服を買うならAで決まり!!お問い合わせは... |
| B | カテゴリB | 高級食材のB | 高級食材を買うならBが安い!! |
| C | カテゴリC | 車のパーツはC | パーツの取付も行います!! |
すべてのtitleとdescriptionを収集すると、手動でカテゴリを定めたデータ数と等しいデータ数になるので約470の学習データが集まったことになります。
学習
今回はBERTを用いて学習・予測を行いました。
BERT(Bidirectional Encoder Representations from Transformers)とは2018年にGoogleから発表された自然言語モデルです。
また、私自身BERTに精通しているわけではないので、今回は勉強も兼ねて「BERTによる自然言語処理入門 ―Transformersを使った実践プログラミング」を参考に学習を実施しました。
第6章にBERTによる文章分類というものがあるので、そちらを一部書き換えて使用しました。
工夫したポイント
モデルやpre-trained modelは本で紹介されている通りのものを使用しましたが、18カテゴリへの分類問題で正解率が62%前後しか確保できていないため、この精度では運用できないと判断し、以下のような工夫を行いました。
工夫したポイント① 2種類の予測モデルを用いる
精度改善のために元々1つの予測モデルで学習・予測行っていたものを、2つの予測モデルで行うように変更しました。それぞれの予測モデルは以下のような役割を担っています。
| 予測モデル | 役割 |
|---|---|
| 予測モデル1 | データ量が多いカテゴリを予測するモデル。簡単な予測問題を間違えない。また、データ数が少ないカテゴリはまとめて「その他」と予測する。 |
| 予測モデル2 | 予測モデル1で「その他」と予測されたデータを、それぞれのカテゴリに割り振る予測モデル。データ数が少なく難しいカテゴリに対して予測を行うので正解率は低い。 |
手動で割り振られた約470データのカテゴリは以下のようになっており、学習に使用できるデータ量がカテゴリごとにばらつきが大きいことがわかります。 またデータ量が少ないカテゴリは、多くの場合低い精度を示していました。
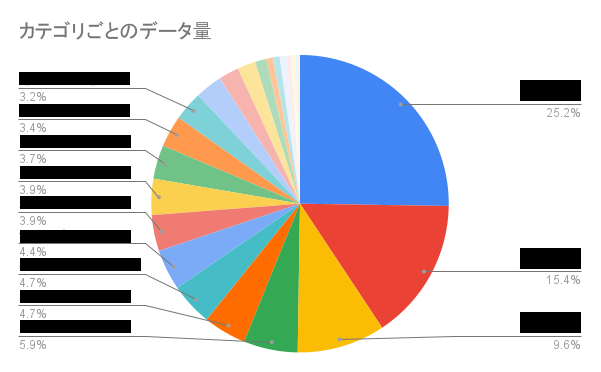
予測モデル1では、データ量が少ないカテゴリは「その他」とまとめてしまい学習を行いました。予測モデル2では「その他」をより細分化するための学習を行いました。

しかしながら、この方法だけではデータ量が少ないカテゴリを学習している予測モデル2はこれまで通り低い精度でしたので、以下に示す工夫ポイント2を導入することにしました。
工夫したポイント② 自信のない予測は、後で人手で確認するようなフローにする
これまでは出力されたカテゴリの全てを信頼するようにしていましたが、一定の信頼値以下の予測に関しては後で人手で確認するというフローを導入しました。

そうすることで、予測結果の信頼値が高いものは予測結果がそのまま採用され、信頼値が低いものは人が後で確認するという流れになりました。また人が後で確認してカテゴリを定めたデータは、学習モデルの精度向上のための再学習に使用することができます。
工夫したポイントを導入した結果
元々正解率が62%だったものが上に示したような工夫ポイントを導入することで正解率は91%まで向上しました。また、そのうち2割ほどが人手での再確認を要するものとなりました。
さいごに
工夫したポイント②の「自信のない予測は、後で人手で確認するようなフローにする」はちょっとせこいのではないか?と思われる方もいるかもしれません。しかし、残りの全てのクライントに手動で割り振ることと比較すると業務量としてはかなり削減できることになっています。(8割軽減)
「機械にできる簡単なタスクは機械に任せてしまって、人間は本当に考えないといけないような業務に集中できる」ような分析やサービス作りに携わっていきたいなぁと改めて感じた業務でした。
最後までありがとうございました。
P.S. 工夫ポイント1はlossの設計をうまくやれば不要だったりするのかなぁなんて思ったり...