ソーシャルPLUS の開発チームでインフラエンジニア をやっています ![]() id:mayuki123 です。今月からフィードフォースから分社化をした株式会社ソーシャルPLUS の所属となりましたが、仕事内容は変わらずにサービスのインフラ改善を進めていく事になるかと思います。
id:mayuki123 です。今月からフィードフォースから分社化をした株式会社ソーシャルPLUS の所属となりましたが、仕事内容は変わらずにサービスのインフラ改善を進めていく事になるかと思います。
2019年11月に技術スタックを整理してみたという記事から2年弱経過していますが、ソーシャルPLUSのインフラ環境は、一部アプリケーションについてはコンテナ環境を Amazon EKS にホスティングして本番運用するようになりました。あと数ヶ月ほどで全ての環境がEC2からコンテナに置き換えられると良いなと思っています(願望)。
そして、既に利用されている機能の一部を Amazon EKS に移行して、しばらく経過した時にアプリケーションでネットワークエラーが稀に発生していました。原因調査をした結果が CoreDNS の負荷によるものと発覚するまでのトラブルシュートの流れについて、記事として書き残しておきます。
発生していた事象
ソーシャルPLUSでは、バックエンドのアプリケーションでエラーが発生した時に、Bugsnag を利用して Slack 通知するようにしています。ある時にMysql2::Error::ConnectionError が発生しました。単発のネットワークエラーの場合はアプリケーションがリトライする事でサービス影響がない事も多く、一時的な問題と思って静観する事があるかと思います。しかし、また数日後に同じ事象が発生しました。
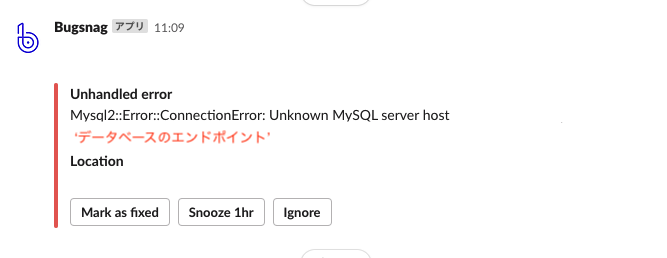
ハインリッヒの1:29:300の法則のように、ちょっとした異常を見落としていると重大なサービス障害となってしまう可能性があるので、原因調査を始めます。
Datadog を活用した原因調査
ソーシャルPLUSでは、モニタリングサービスの Datadog を利用しているのでメトリクスやログの調査を出来るようになっています。どこが原因かを探り始めました。
アプリケーションの負荷状況
まずはアプリケーションで利用するサーバの負荷状況を確認する所から始めました。Mysql2::Error::ConnectionError が発生した時刻は EKS の Node の CPU 使用率が 70% ほどで、アプリケーションで負荷のかかる処理の最中でした。また、データベースの負荷は少し前に負荷対策の改善をした事もあって、今回の事件の犯人ではなさそうです。他にもEC2 と DB 間でネットワークのボトルネックがないかなどの確認はしましたが、CPU 使用率が高い以外の問題は特に見つかりませんでした。完全犯罪でしょうか。
EKS 上のコンテナの調査
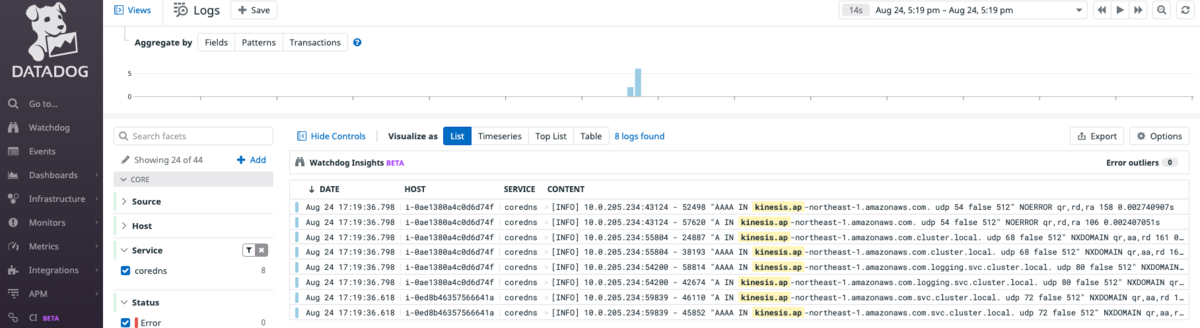
サーバ単体の問題ではないとすると、Amazon EKS で何か起きている事を疑うことにしました。EKSで動かしているコンテナのログは Datadog Logs に送っているので、エラーが発生していたアプリケーション以外のログ を確認していると、MySQL の ConnectionError が発生した時間帯に下記の Warning のメッセージが出ている事に気づきました。このログは Amazon Kinesis Data Firehose にログを送る Fluent Bit のコンテナで発生しており、エラーが発生してたアプリケーションとは異なるノードに存在してました。
[yyyy/mm/dd hh:mm:ss] [ warn] [net] getaddrinfo(host='kinesis.ap-northeast-1.amazonaws.com'): Name or service not known
同時刻に特定のアプリケーション以外のコンテナも影響を受けていることから、EKS の中で問題がありそうです。元々、EKSに関する技術ブログは目を通すようにしていた事もあり、Kubernetes の DNS の名前解決で問題が発生する場合があるというのは知っていたので、CoreDNSに焦点を当てて調べることにしました。アウトプットをしてくれる人たちには、いつも感謝をしています。
- Production Ready EKS CoreDNS Configuration | by Serkan Capkan | Cloutive Technology Solutions - Tech Blog | Medium
- EKSでDNSを安定させるために対応したこと - Chatwork Creator's Note
- スマホゲームの API サーバにおける EKS の運用事例 | エンジニアブログ | GREE Engineering
EKS のCoreDNS の調査
Datadog Agent で Kurbernetes の各種メトリクスを収集していて、EKS の CoreDNS の状況も Datadog の Metric Explorer で確認する事が出来るようになっています。
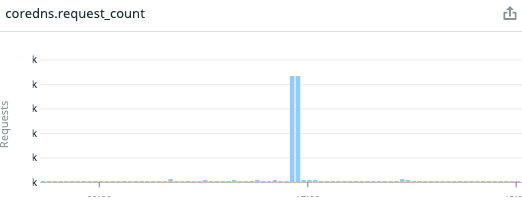
coredns.request_count を確認すると特定の時間帯で CoreDNS へのリクエストが多い状態で、このタイミングでの CoreDNS Pod の CPU 負荷は10%前後でしたが、それ以外に不審なメトリクスは存在しませんでした。まだ事象の原因との確信は持てないですが、負荷がそれなりにかかっていることは確かなのでリクエストが多くなる理由を調べます。
CoreDNS のデバッグログの有効化
まずは CoreDNS のデバッグログを確認したいとなるかと思いますが、EKS の CoreDNS はデフォルトだとデバッグログの出力がオフの状態のため、どのようなリクエストが到達しているのかは確認する事ができません。CoreDNS のログを有効化する方法は AWS のナレッジベースにある記事に方法が記載されています。
この記事によると、Namespace(kube-system) に Configmap (coredns) があるので、Corefile 設定に log を追加するとデバッグログ が出力されるようになります。
# kubectl -n kube-system edit configmap coredns
kind: ConfigMap
apiVersion: v1
data:
Corefile: |
.:53 {
log # Enabling CoreDNS Logging
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
...
上記の設定をすると CoreDNS のPod の標準出力にデバッグログ が出力されるようになります。私の触っていた EKS の環境の場合は、数分ほどで CoreDNS の Pod で reload が発生して元の設定(デバッグログ がオフ)に戻るようになってました。
Kubernetes の名前解決について
次にKubernetes 上のコンテナはどのように名前解決するのかを知っておく必要があります。Kurbernetes の Pod の DNS リゾルバー(/etc/resolv.conf) のデフォルト設定は下記のようになっています。
% kubectl exec fluent-bit-46zvl -- cat /etc/resolv.conf nameserver 172.20.0.10 search logging.svc.cluster.local svc.cluster.local cluster.local options ndots:5
この状態で Fluent Bit のコンテナから Amazon Kinesis の API エンドポイントに疎通する場合は、CoreDNS に8回のリクエストが発生します。これは、IPv4 , IPv6 の2種類の名前解決を search の数だけ名前解決を試みた後で EKS 外に名前解決をする設定になっているからです。この設定になっているおかげで Kubernetes の Service を使った名前解決が出来るようになっています。
また、options ndots:5 の設定は . の数が 5個以上の時は最初から外部に名前解決するようになります。そのため、Amazon Aurora や ElastiCache などのデータベースへの クラスターエンドポイントは . の数が五個以上あるので、CoreDNSへのリクエスト回数は少なくて済みます。ここを意識しなくてよいのはありがたいですね。
ソーシャルPLUSというプロダクトの特性上、EKS 内のアプリケーションから外部サービスの API を実行する機会が多々あります。特定のタイミングで外部のサービスに大量のAPIリクエストを実行した際に、CoreDNS へのリクエストが増大してしまい不安定になってしまったのではと考えられます。
CoreDNS の負荷軽減
Kurbernetes 上のコンテナの名前解決を知ると、外部サービスのAPI を実行する際には CoreDNS へのリクエストが多くなる事が分かりました。ここで、CoreDNS へのリクエスト数を減らす方法は下記の二つがあります。これも AWS のナレッジベースに方法が記載されているので、詳細は下記の記事を読む方が良いと思います。
ドメインの末尾にドット (.) を追加する
接続先のドメインの最後に . をつけると、EKS の内部で名前解決を複数回しないようになり、CoreDNS へのリクエストの総数が減ります。一例をあげると、example.com ではなく、 example.com. とする事で最初から EKS の外部に名前解決をしてくれるようになります。ドメインが SDK の内部で定義されているような場合など、変更出来ない場合はこの方法は利用出来ないかと思います。
/etc/resolv.conf で ndots:1 の設定をする
/etc/resolv.conf に options ndots:5 とデフォルトで設定されている数値を 1 にする事で、ドメインに . が含まれている場合は常に EKS の外部に名前解決するようになります。Kubernetes の Manifest に spec.dnsConfig パラメータを設定する事で Pod 単位で変更が出来ます。ただし、この設定をすると EKS 内部で名前解決をしなくなってしまいますが、<name>.<namespace>.svc.cluster.local. のように最後に . をつけると名前解決出来ました。Kurbernetes の Service の数が多いとこの方法を周知させるのも大変だと思います。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hoge
spec:
template:
spec:
dnsConfig:
options:
- name: ndots
value: "1"
その他の CoreDNS の負荷軽減の方法
上記の二つの方法は CoreDNS へのリクエスト数を減らすことで、負荷を軽減するようなアプローチでした。CoreDNS の Pod 数はデフォルトで 2個となりますが、CoreDNS のPod をオートスケールする手段もあります。
また、Daemonset で DNS キャッシュをノード単位で配置するという方法もあります。
この辺りは他の方が書いた技術ブログも多くあるかと思うので、この記事では特に説明はしないです。
最終的な結果
ソーシャルPLUSでは最終的に根本原因の CoreDNS へのリクエスト数を減らすために /etc/resolv.conf で ndots:1 の設定をするようにしました。この設定をアプリケーションの Pod に適応した所、CoreDNS へのリクエスト数は 25% ほどと目に見えて減少させる事が出来ました。キャプチャは載せてないですが、CoreDNS の Pod の CPU使用率も 以前の半分ほどになったので、負荷軽減の目的は達成しました。
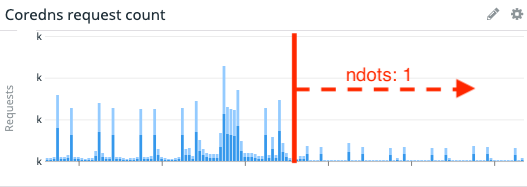
ここまで、確信を持てないまま CoreDNS の負荷軽減に取り組みましたが、元々のネットワークエラーであった Mysql2::Error::ConnectionError のエラーは再発しなくなりました。また、EKS 上の他のコンテナも Name or service not known のような名前解決が出来ないといったエラーも発生しなくなりました。CoreDNS の負荷を減らす事で悩まされていた問題の解消が出来たと思います。今回のように比較的早い段階で気づく事が出来たので、お客さんへのサービス影響のある問題に発展せずに済みました。
今後、利用者数が増えてより負荷のかかる状況になってきた時には再発する可能性はありますが、早い段階で気付けるように日々確認するダッシュボードにメトリクスを追加するようにしています。その時がきた場合は CoreDNS の Pod 数の調整や DNS キャッシュの導入が必要になりそうです。
おわりに
最終的には Pod の DNS 設定を調整するだけでネットワークエラーは解決しました。この記事では、結果だけではなくて解決に至るまでの経緯をメインにまとめてみました。実施していて良かったと思うことを下記にまとめます。これらの事が出来ていなければ、今回のようなネットワークエラーはたまに発生する事象として、根本原因の追及は出来なかったと思うので、サービスのオブザーバビリティを整備する事や日々の情報収集は大事ですね。
- アプリケーションのエラーを Slack に通知していた
- Kurbernetes のメトリクスを Datadog で確認できる状態だった
- コンテナのログを一元的に Datadog Logs で閲覧できるようにしていた
- 他の人の技術ブログから Kubernetes の CoreDNS が不安定になることを知っていた
この記事に間違っている内容や、もっと良い改善方法がある事をご存知の方がいましたら、優しく教えてください。
おまけ
現在、ソーシャルPLUS では作りたい機能が山ほどある状況でまだまだ成長するサービスになると思うので、成長を続けるサービスに携わりたいエンジニアやデザイナーのご応募をお待ちしております!サイトにはまだないですが、インフラエンジニアも近いうちに募集をする事にはなると思います。
フィードフォース の他のサービスもエンジニアを募集してますので、興味があればご応募お待ちしております!